When we pay for a service, we expect a certain level of quality in return. When that service quality is high enough, everything is fine. Until one day when we feel it isn’t up to scratch anymore, what then? What went wrong? Who’s paying for a sub-par service?
But who gets to say what’s fine? What is good and correct? Furthermore, how do you know when it’s wrong, and what do you do when it’s wrong?
Seeing Data as a Service
In business terms, this is why we have contracts. In legal speak, a contract is seen as a formal agreement between two entities – this is not legal advice, I am not a lawyer, and I’m summarising for illustrative purposes only.
In data terms, where we see data as a service, the data contract is an agreement of service, a compensation mechanism, a service level agreement, a description of expected standards – an alignment of the data provider, and the data consumer, and a communication channel to facilitate quality assurance and change management.
In a recent Business Unfiltered podcast, Mercer & Jeff Sauer – (17 mins) talk about how business contracts ease the termination of a business relationship. This provokes thoughts around how data contracts are actually used to maintain, and develop, rather than close the relationship between the data provider and data consumer.
We find that in reality, you probably need a data contract because the relationship between data provider and consumer has gone south already. That’s easier to achieve than you’d comfortably imagine…
Where did Data Contracts come from?
Data contracts got hyped when the implementation of data mesh suddenly took over. They go beyond just GA data or GMP data and focus on ensuring data delivery and data quality from the source/owner to the destination/consumer.
As a result, they go beyond just the APIs that serve data, as Chad Sanderson has pointed out. We encourage and advocate taking ownership of data as a matter of sensible and necessary governance. But with this motivation, have you ever come across a table, a saved query, a sheet, or even a Looker Studio blend and thought “Nope, that’s clearly not needed anymore”? What if someone has created an “unintentional API” through ad hoc ELT/ETL…? Ownership is nothing without a data dictionary, an asset library, and a full understanding of the source and destination of the data. This is when The Bad Things happen.
This is one use case where data contracts will save the day. There are many more, let’s explore some of them.
Data Contracts – we already use them without realising
Google Analytics (GA) has nearly always stipulated no PII – you can’t collect email addresses, names, and so on. It also states a data collection rate and volume. The schema for data collection is well documented. The GA terms of use are an example of a contract – a data contract in human words – the written phase of a data contract.
As an industry, we need to recognise the utility of data contracts as key parts of robust, automated solutions that scale. Start to think of data as a product, data as a service, and how we expect services to be delivered, how a product needs to be of sufficient quality, and how to integrate across these systems.
The concept isn’t demanding to grasp, the details and possibilities are very exciting – there’s a strong upside to adopting data contracts.
Data Contracts as specifications
A primary function of a contract, data or otherwise, is to set expectations. The definition of what, how, and why is required to establish the functionality and semantics of the data and the interface to the service. This is essential to deliver against the principle of self-serving data.
As data changes, as will contracts, we’ll talk QA and Change Management later. For now, assuming there is no current change, the specification aspect of the contract enables system stabilisation. We’ve agreed on using version x.yz of the contract so we can confidently build systems and deliver production-ready deliverables.
Anyone with experience in software development as well as data practices will instantly recognise the process: code/data reviews, checking, and version management. This is an essential part of data engineering, not treating data as an afterthought means you automatically defend against upstream changes impacting data quality.
As we treat data services like an API, the data contract is an API with documentation. A solid contract leaves no room for interpretation. The documentation is a strict definition of the service but it’s in no way a blocker or a barrier to using the data.
Tools exist that handle the needs of data service providers and consumers – take a look at Data Mesh Manager as an example. Reducing complexity, increased resilience, robustness, and data quality isn’t onerous.
Additionally, one of the most common and adaptable templates was released by Paypal, which we can easily adopt if/when we provide such services to our clients.
Data Contracts for Data Quality
Many organisations will centralise the data collection destination in a data warehouse. This will likely require a data model that’s designed and optimised for ingestion. This is certainly true of the GA4/BigQuery integration:
The raw GA4 data in BigQuery is not designed for consumption.
The data model is optimised for ingest and is largely unsuitable for most workloads. It fails the test for data quality. Flattening, joining, cleaning, redacting, and shaping the data produces a production-ready data set that is good quality. As your analytics footprint grows, so will the data landing in BQ. How do you maintain the quality of the data in this changing, growing environment?
Unfortunately, in many deliveries, we (the “royal we” as an industry) still do not perform quality tests, which is a fundamental requirement of data contracts, and also a great opportunity for upselling! We are strongly of the opinion that they should be part of a deliverable from day 0, alongside data dictionaries, for ALL data engineering engagements.
During MeasureCamp London ‘23, Jordan Peck (Snowplow) asked how companies ensure data quality, and what processes and tools are used. Fair question – the tooling you use isn’t limited to one choice, and ideally provides you with automation to drive scale.
Take a simple example like a Looker Studio dashboard. A reasonable but often absent QA asset is a data dictionary to define what data is required. Beyond dimensions and metrics, consider segments, filters, and data sources. The data dictionary needs to fully qualify exactly what data is expected.
Okay, got a dictionary? Good. Make sure it’s maintained, you’ll be grateful when it comes to migrating from UA to GA4. Thank me later. Do we have everything we need to support the dashboard use case now? Clearly not. That’s a stakeholder interview question – what is the data for. Essential to make sure the data has a purpose – if there is no business value to the data, why bother? If there is a purpose, is the data fit for use? Consider practical use as well as ethical and legal/regulatory correctness – this will be a go/no go step in the QA process
Additionally, you need to define expected value ranges for outlier and anomaly identification. What’s the expected and required update frequency minimum and maximum? The dictionary will also cover governance to define who has access to the data – important for regulation. This aligns with the need for citations – defining the data source, and owner in a technical, and business owner sense.
Data Contracts for Change Management
We can use contracts to evolve the relationship and change requirements. From the simple example in the previous section, the stakeholder interview needs to be an open communication pipeline. Either quarterly to review fitness and purpose, and/or an open channel for driving change and optimisation in the data activation.
As businesses change, so will the data requirements. Don’t expect contracts to remain static but make sure change is conducted in a controlled and managed with rigorous process. Manage change and version control of contracts as you would for any production-grade software development.
The change management aspect will blend the skills of the engineer, the salesperson, architect, data engineer, data viz & BI – it’s cross-discipline to ensure not just that the right change, but that we understand what change is actually possible, and that gets baked into the contract.
Without contracts, change is initiated by the consumer or provider without consultation. This is chaos, unmaintainable data anarchy. Doesn’t end well. Ever.
OR change doesn’t happen at all because providers are consumers, don’t have a relationship, and don’t understand the art of the possible. This is static and a slow grind to the bottom of the ocean.
Contracts facilitate change. They foster communication – a valuable trait in a complex business system.
Data Contracts and CI/CD pipelines
Anecdotally, we observe data contract usage in more mature organisations – mature in a digital maturity sense. This is well-aligned with automated deployment through Continuous Integration/Continuous Deployment/Delivery (CI/CD) pipelines.
That said, clarifying how they interact with each other is a useful definition of how an organisation makes decisions and activates data.
The CI/CD pipeline is a tool, a means to operationalise the framework around data.
Whereas data contracts are much more a cultural shift in an organisation in regards to data, contracts are implemented at the semantic level of the data organisation.
Contracts represent the data service to be consumed – not how, that’s the pipeline end result. That’s with the data consumer in their own domain, for their own use cases.
Contracts provide centralised Data Governance. Distributing computational governance to domain teams, allowing freedom and self-serve choices in how the data is used allows for overall computational governance to be shared efficiently.
Automation
As the verbal-to-written contract transformation proceeds via the production of a dictionary, consider moving to a semi-automated approach. Can you automate the data dictionary creation? What if you reverse engineered workspace logs for a Looker Studio dashboard?
This is an important step up – verbal and written contracts have benefits, but equally exhibit pitfalls to be avoided as described by Great Expectations in the 3 phases of data contracts:
“Written contracts create a tension between flexibility and compliance. Broadly speaking, most organizations end up with either a “data wiki that’s chronically out of date” or “data pipelines that can’t be changed without lengthy review involving the compliance/privacy/governance/legal team.”
What does the end-to-end automation look like and how does the process flow? Who are the actors and stakeholders? Let’s explore a possible manifestation below:
From left to right, the service consumer and providers are working closely together to define new features—often in a product management tool such as Jira or Asana—which will eventually be logged as issues in the corresponding version control repository, e.g., GitHub or Bitbucket. The contract additions and changes are focussed on foundational elements at this point: the schema changes naturally, and privacy first obviously. That would manifest itself in potential requests from the data product management team and the product owner in capacities such as modifying the way that the front-end collects first-party data, for instance, which will then start a domino effect of changes required to be made to the data pipeline.
The implementation of the change(s) is the domain of the data service provider. The contract elements relate to data quality, and consistency, to name a few. These will drive the service-level objective and agreements based on established or newly created service-level indicators.
At deployment, the contract establishes these as tests. Notice the Data Steward responsibilities book ending the domain of the data service provider.
With the feature/issues delivered, the contract is used as an API with documentation to consume the data appropriately, and then activate the asset for gain.
Close – the many roles of Data Contracts
These use cases can be expressed in terms of a data life cycle from dictionary creation to establishing stakeholders, input, and defining the contract, through change management in a CI/CD deployment. This reflects the notion of the three phases of the data contract as suggested by Great Expectations – the verbal phase, the written phase, and the automated phase.
The verbal phase, an informal agreement person to person is where we start. We progress to the written form as the service provider and consumer align on the value of the data. As the data provision and consumption scale to a point, the functionality of the contract is automated to provide seamless workflow integration.
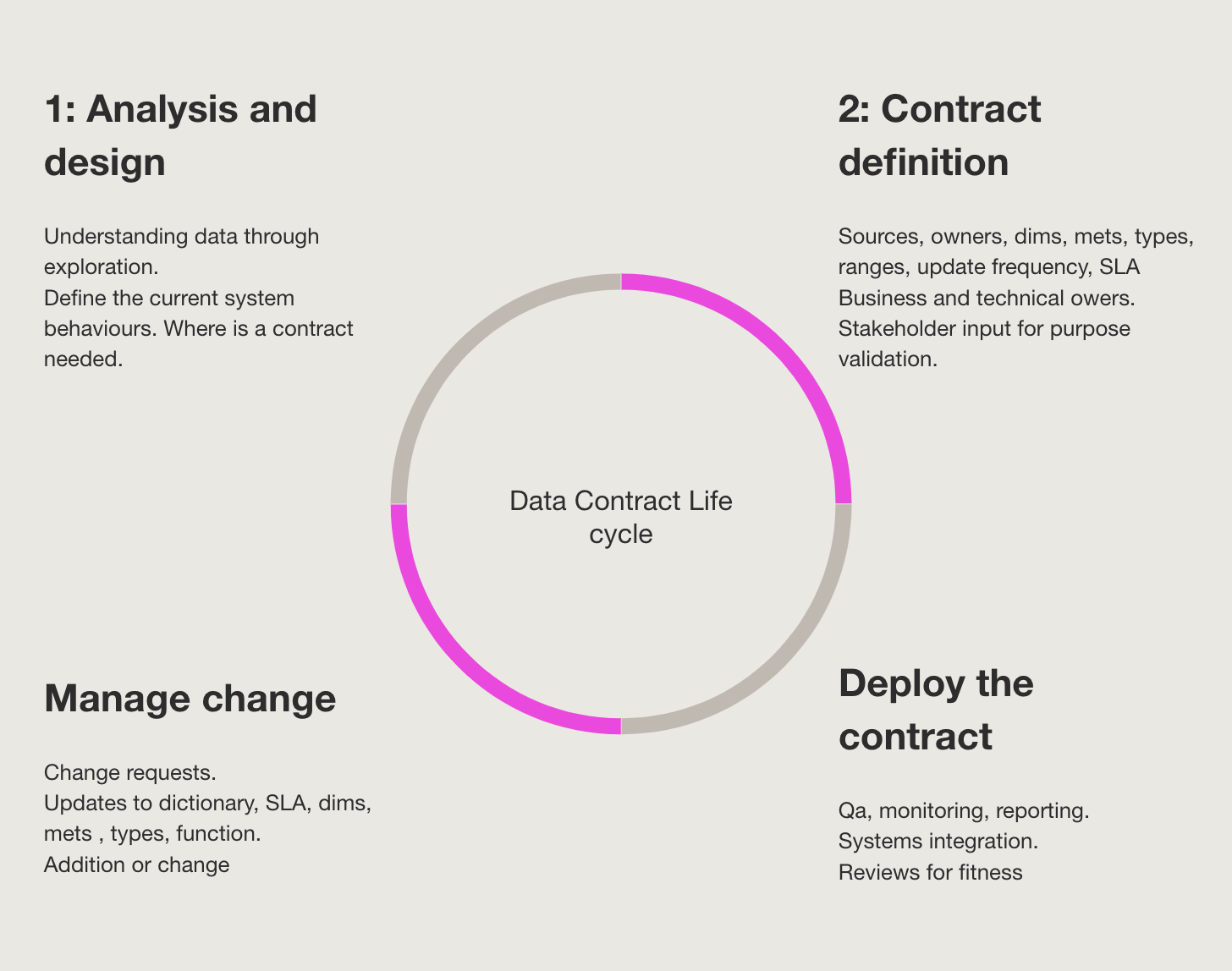
Having a data contract isn’t the end goal. It’s a means to ensure the quality of services so the data has maximum value.
See the contract not as a restriction but as a tool that is a supporting asset, is open to change, a mutual value add to providers and consumers.
Similarly, Privacy Regulation isn’t anti-business. When it’s properly understood, it’s pro-consumer and a customer-centric business thrives,
Understanding how Data Contracts give you the same competitive advantage is a journey that will reduce (technical, organisational, political, and commercial) pain, prevent disaster, promote collaboration, foster change, and engineering discipline.
About the authors

Doug Hall
Strategic DOER
Formerly as the VP of Data Services and Technology at Media.Monks in EMEA, Doug led a team of data analysts, engineers, and scientists who helped clients transform their digital marketing and analytics capabilities.
With over 25 years of experience in the data and technology field, he has a proven track record of delivering innovative and impactful solutions that drive business growth and customer satisfaction.

Arman Didandeh
Senior Director, Data & ML Systems @ Media.Monks
Coming from a full-stack software development background, Arman has been involved in the design and implementation of many cloud-native data and AI products for startups as well as mid-market and enterprise clients.
With an innovation lens, Arman is always curious about means and measures to challenge the status quo and to find novel solutions for business problems with high ROI.

