I’m back from my vacation in Romania, and happy I’ve managed to escape the 40 degrees (Celsius) and come back to a very suspicious looking summer here in Malmo.
Since I had some down time, I managed to analyze and unpack the EU AI Act, talked a bit to Aurelie Pols last week on the topic, and was finally able to sit down and write about it. Also used some of her slides from her Measure Summit Presentation.
Besides Aurelie, big thanks to Siobhan Solberg, Fabrizio Bianchi, and Robert Børlum-Bach for giving this article a read before I hit send. They’re the experts on these topics, I’m just a practitioner working and building using AI, and my goal here is to help people just like me understand the EU AI Act.
As most of you know by now, for the last 2-3 years, my world has revolved around AI models and many types of data sources, and I’ve been constantly striving to deliver the best for my clients, partners and my employer.
I am absolutely committed to innovation, to taking calculated risks, and to exploring every transformative possibility AI offers us. But there’s a hard line.
We cannot pursue this at the cost of personal data, nor through harm, misunderstanding, or a lack of empathy towards people. And definitely not just because we feel we “have to” build with AI at all costs to make a quick buck.
This is exactly why the EU AI Act matters so much: it compels us all to think about responsible building, transparent products, and cultivating trust with the market.
So, again: this is my interpretation as an AI practitioner. I’m not a DPO or legal counsel, and yes, nuances exist, and I could be wrong. My aim is to help you understand the Act through a practical lens. (NB: For specific legal advice, call your actual lawyers, that’s their job. Or, why not, read it yourself?)
So, let’s skip the legalese and go straight to what you actually need to know.
Fair warning, it’s a bit lengthy. I tried LLMs to summarize, but the result was crap, so you’re getting the full version.
Table of Contents
The EU AI Act: What it is, why it matters, and when it actually applies
The EU AI Act is the world’s first comprehensive legal framework for artificial intelligence. (took the phrasing from this article)

The Act ensures AI systems placed on the European market, or used within the EU, are safe, transparent, and respectful of fundamental rights. This regulation directly impacts how AI is conceived, built, and deployed, especially if you operate in, or sell to, the EU.
What is defined as an AI System under the EU AI ACT?

Under the Act (Article 3, further explained by Recital 12), an “AI system” is fundamentally defined by these characteristics:
- It’s a machine-based system: Meaning it runs on hardware and/or software.
- It operates with varying levels of autonomy: It has some degree of independence from direct human involvement and can operate without constant human intervention. This distinguishes it from simpler, purely rule-based software where every step is explicitly defined by a human.
- It may exhibit adaptiveness after deployment: This refers to self-learning capabilities, allowing the system to change or improve its behavior while in use. Importantly, a system doesn’t have to be adaptive to be considered AI; it’s an optional characteristic.
- It infers from inputs to generate outputs: This is a key distinguishing feature. It means the system can derive models, algorithms, predictions, content, recommendations, or decisions from data or encoded knowledge. This “inference” goes beyond basic data processing by enabling learning, reasoning, or complex modeling.
- Its outputs can influence physical or virtual environments: The results it produces can have a real-world impact, whether that’s a decision, a piece of generated text, or controlling a robot.
In simpler terms: If a software or system can learn, reason, or model patterns from input data, and then produce outputs (like predictions, content, or decisions) with some independence (autonomously), the EU AI Act likely considers it an “AI system.”
This includes everything from traditional machine learning algorithms to sophisticated large language models. The key element is the capacity to “infer” rather than just executing pre-programmed, static rules.
EU AI ACT Timelines
The Act entered into force on August 1, 2024. But its full impact rolls out in stages:
- February 2, 2025: Prohibitions on unacceptable risk AI systems (Article 5) became applicable.
- August 2, 2025: Rules for General Purpose AI (GPAI) models, including most LLMs, become applicable (i.e, transparency on training data, preventing illegal content generation).
- August 2, 2026: The bulk of requirements for high risk AI systems become applicable.
The Act operates on a risk-based approach.
This means that compliance obligations directly scale with an AI system’s potential to cause harm. A higher risk means stricter rules, simple as that.
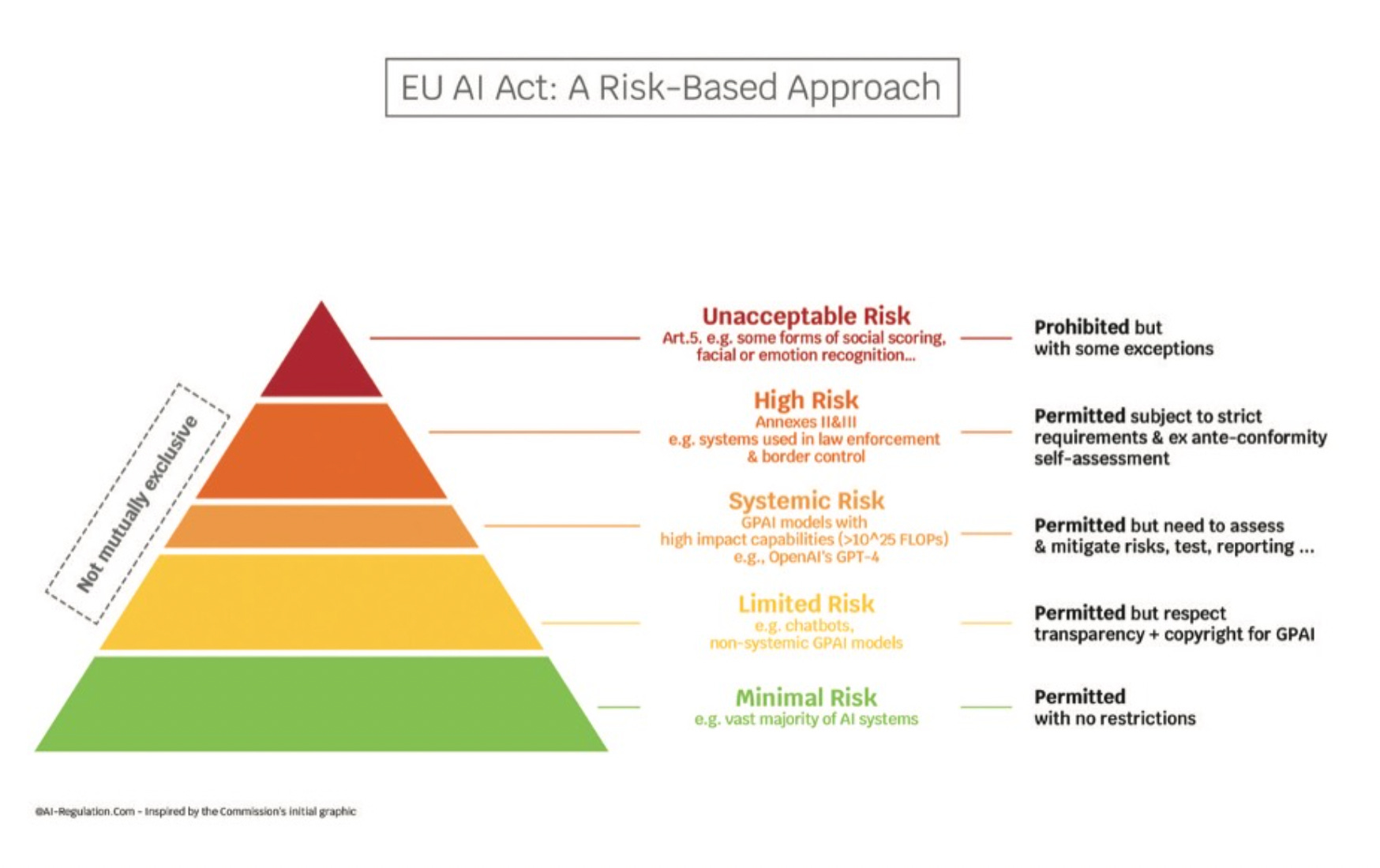
This is how “risk” is described within the act:
- Unacceptable Risk AI: These AI systems are fundamentally incompatible with EU values and are prohibited.
- Example 1: A system designed for social scoring, where an AI evaluates individuals based on their online behavior, political views, or social connections, and then automatically restricts their access to housing, jobs, or public services. That’s a clear line in the sand, explicitly forbidden by the Act (Article 5).
- Example 2: AI systems that use subliminal techniques to manipulate behavior, especially exploiting vulnerabilities. Picture an app specifically designed with AI to trigger gambling addiction in minors or to coerce vulnerable individuals into harmful purchasing decisions without their conscious awareness. That kind of manipulative AI is strictly banned.
NOTE: These prohibitions, clearly detailed in Article 5 of Regulation (EU) 2024/1689, have been applicable since February 2, 2025.
- High Risk AI: This category refers to AI systems that pose significant risks to health, safety, or fundamental rights. This is where most of the operational heavy lifting will happen for businesses. A mandatory conformity assessment is also required before your system goes to market.
Why am I saying that this is where most things will happen for a business?
Fabrizio pointed out that I need to clarify this. It’s because there is a VERY VERY thin line between low/minimal risk and high risk systems. On one hand we have greed, sometimes lack of awareness, that will cause companies to not stick to what their AI System intended purpose is, and on the other hand, when you build AI Agents, wrappers and other tools of such, you do not have control over the model, or how the model/agent will evolve, unless of course, robust guardrails are in place.
Let me paint a picture for you here to let this sink in.
Agent A was built to monitor social media mentions. Agent B was built to reply to customer inquiries. Both got abandoned, the deployer/provider left the company, and the agents were not off-boarded and they’re still running. Now Agent A is feeding data to Agent B, and Agent B is auto responding to mentions that Agent A flagged as “urgent” based on 8mo old criteria.
Abandoned agents talking to other abandoned agents, creating feedback loops, developing their own little “digital corners” in our infrastructure.
And unlike traditional technical debt that just slows you down, this ghost web we are creating might start making its own decisions about your business. Imagine discovering your company’s been automatically approving certain types of things for months because three different abandoned agents created an accidental approval chain.
And in the end the debugging question evolves from “what’s this code doing?” to “what are these agents doing when we’re not looking?”
Let’s take some examples here of High Risk AI Systems:
- Example 1: An AI tool used in employment decisions, for example, an automated system that screens job applications based on predicted performance, or an AI that monitors employee productivity and impacts their promotion opportunities.
- Example 2: AI systems for access to essential services, like an automated system determining an individual’s eligibility for a loan, insurance, or public assistance. A marketing team using AI to segment customers for credit offers would need to ensure this system meets high risk obligations if it materially affects an individual’s access to credit.
- Example 3: AI components used in critical infrastructure, such as systems managing traffic control, energy grids, or water supply. Even a small AI anomaly here can have cascading, dangerous effects.
The specific criteria for high-risk AI are outlined in Article 6 and Annex III of the Act.
NB: For high risk AI, you, as a provider or deployer, must:
– Implement robust risk management systems
– Ensure high-quality data governance for all training and testing data
– Maintain comprehensive technical documentation and logging
– Ensure human oversight mechanisms are in place, and strive for high levels of accuracy, robustness, and cybersecurity.Note: Most of these requirements become applicable on August 2, 2026. This is the critical date for a significant compliance push.
- Limited Risk AI: These systems require users to be informed about their AI interaction or the AI-generated content.
- Example 1: A chatbot on a customer service portal. Users must be explicitly informed they are interacting with an AI, not a human.
- Example 2: Generative AI models used by a marketing team to create ad copy, product descriptions, or images. That content needs clear labeling as AI generated, ensuring consumers aren’t misled.
- Minimal/No Risk AI (Minimal New Obligations): Simpler AI Applications for every day use, such as spam filters or content recommendation engines (outside of high-risk contexts), fall into this category, facing minimal new direct obligations.
For High Risk AI Systems, a mandatory conformity assessment is also required before your system goes to market.
Let’s stop here for a bit, because this is very important for most people to understand.
When we talk about a “mandatory conformity assessment” for high risk AI systems, we’re talking about the formal process a Provider (the vendor) must undertake to demonstrate that their AI system meets all the requirements of the EU AI Act before it’s placed on the market or put into service in the EU. Chapter III of the EU AI ACT.
Some important terms here to remember here:

The conformity assessment is basically a structured approach that involves demonstrating compliance across several key areas detailed in Chapter III, Section 2 of the Act (Articles 8-15), including:
- Risk Management System (Article 9): You need an established, implemented, and documented system for continuously identifying, analyzing, evaluating, and mitigating risks throughout the AI system’s entire lifecycle.
- Data Governance (Article 10): Covers the design choices and technical measures taken to ensure your training, validation, and testing datasets are relevant, representative, free of errors, and complete to the best extent possible. It’s also about addressing potential biases.
- Technical Documentation (Article 11): You must create and maintain comprehensive documentation that provides all necessary information about your AI system, its purpose, its components, its development process, and its performance. This includes detailed descriptions of your data sources, the model architecture, and risk management measures. This documentation needs to be available to market surveillance authorities for at least 10 years after the system is placed on the market.
- Record-Keeping (Article 12): High risk AI systems must automatically log their activity throughout their lifetime, allowing for traceability of results. This is essential for post-market monitoring, investigating incidents, and proving compliance.
- Transparency and Provision of Information to Deployers (Article 13): You must provide clear, concise, and understandable instructions for your deployers on how to use the AI system safely and as intended. This includes information on the system’s capabilities, limitations, and any necessary human oversight measures.
- Human Oversight (Article 14): High risk AI systems must be designed to allow for effective human oversight during their operation. Not to function, but to be enabled if necessary. This means human users should be able to intervene, correct, or override the AI’s decisions where necessary.
- Accuracy, Robustness, and Cybersecurity (Article 15): The AI system must be developed to achieve appropriate levels of accuracy, robustness (resilience to errors or inconsistencies), and cybersecurity throughout its lifecycle. This protects against both intentional attacks and unintentional failures.
Who is conducting the mandatory conformity assessment?
The Act offers two main pathways for conformity assessment, depending on the specific type of high risk AI system:
- Internal Control (Self-Assessment) (Annex VI): For most high risk AI systems listed in Annex III (i.e, employment, essential services), providers can conduct an internal self-assessment. This involves the provider verifying their own compliance with the requirements through their established Quality Management System (QMS) and technical documentation. While it’s “self-assessment,” it’s not really a casual check lol, it demands rigorous internal processes and solid evidence.
- Third-Party Assessment (Notified Body Involvement) (Annex VII): For certain highly sensitive high risk AI systems (i.e, some biometric identification systems, or those used as safety components of products already subject to third party assessment under existing EU product safety laws), the involvement of an independent, EU-authorized “Notified Body” is mandatory. These Notified Bodies are external, expert organizations that audit your QMS and technical documentation to verify compliance.
Upon successful completion of the assessment, the Provider (vendors), draws up an EU Declaration of Conformity and affixes the CE marking to the AI system, its packaging, or documentation. This CE marking indicates compliance with the AI Act.

OK, now, let’s take some examples because even my head hurts after unpacking this, lol.
We have a vendor that built a customer reviews scoring tool.
Is it high risk or not? What are the assessment implications?
The tool scrapes reviews to create some scores based on what users are saying about a brand. This is a classic example where the intended purpose and application of the AI determines its risk level and, consequently, the conformity assessment requirements.
Scenario A: Non-High-Risk (Likely, but requires careful justification)
Your AI scrapes publicly available customer reviews (from ecommerce sites, social media, forums) about specific brands. It then processes these reviews using Natural Language Processing to generate aggregated sentiment scores (i.e, a “Brand Happiness Index” of 1-100) and identify common themes ( “users love the battery life,” “complaints about customer service”). This score is used internally by brand managers to track overall brand perception or by marketing teams to identify areas for campaign improvement. No individual user is scored or directly impacted by this. GOOD.
In this scenario, the tool would likely fall under Minimal or Limited Risk AI. It processes publicly available, typically anonymized or aggregated data. It does not perform profiling of individuals, nor does it impact fundamental rights or safety in a significant way. It acts as a business intelligence tool.
Conformity Assessment in Scenario A
No mandatory conformity assessment is required by a Notified Body. However, as a Provider (vendor), you’d still need to ensure transparency (clearly stating the AI processes reviews, how the scores are generated, and its limitations).

Even so, you’d still be wise to implement internal quality management processes, especially concerning data governance (ensuring the review data is relevant and processed fairly) and accuracy, f1 scoring, precision & recall etc, (ensuring the sentiment analysis genuinely reflects the reviews). This is just good practice and builds trust.
NOTE: Now, from my vast experience of this use case, I will say that most review aggregators, or social media scraping tools will, to some degree, collect some personal data (names, locations, preferences, etc) and most tools that scrape this data, if you look at the data exports… it’s a nightmare, so for instance if you API/import this data in your own systems you have to be VERY VERY CAREFUL and do PII redaction or Data Loss Prevention… yes, I am stepping into GDPR here (will talk about this below.)
Scenario B: High Risk (I am ofc exaggerating, but it’s just to paint a picture)
Your AI scrapes publicly available customer reviews (similar to Scenario A). However, this AI system has now developed into something different.
a) it now can generate “customer loyalty scores” for individual users based on their review history, which then directly influences their access to premium support tiers, personalized pricing, or loan eligibility (if linked to a financial service).
b) the “scores” are used by a recruitment firm to evaluate candidates’ “brand alignment” based on their past public comments, directly influencing hiring decisions.
c) the tool identifies and profiles specific individuals based on their negative reviews, flagging to the support team as “difficult” clients / so they will get a different treatment from the support team – btw this is totally possible.
So, once the intended purpose changes, this immediately shifts from Minimal/Limited Risk to High Risk AI. (will explain this more below)

In case a) it affects access to essential private services (credit, benefits) or significantly impacts individuals (pricing). It’s also likely performing profiling of natural persons, which automatically makes it high-risk if listed in Annex III. In case b) it impacts employment decisions (Annex III).
And in case c) it risks becoming an unacceptable risk if it leads to social scoring or harmful exploitation of vulnerabilities (Article 5), but even short of that, profiling for detrimental treatment would make it high-risk.
Conformity Assessment for Scenario B
Since this is now High Risk AI, a mandatory conformity assessment is required. And you can go about it two ways, as we learnt above.
Path 1: Internal Control (Self Assessment)
If your review scoring system falls under Annex III categories like employment or access to services (and not biometric identification), you would follow the internal control procedure (Annex VI).
You, as the Provider, must establish a robust Quality Management System (QMS) for the entire lifecycle of this AI system. This QMS would cover everything from data acquisition (ensuring legal scraping, respecting terms of service), to model development (bias detection in NLP models, validation of scoring algorithms), to deployment (ensuring appropriate human oversight, providing clear instructions on score interpretation to your clients).
You compile extensive Technical Documentation (Article 11) proving that your data governance (Article 10) is sound (i.e., documenting how biases in review language are mitigated, how data is cleaned and anonymized where possible). You’d detail your risk management process (Article 9) for identifying and mitigating risks like discriminatory scoring or misinterpretation.
You’d demonstrate your system’s logging capabilities (Article 12) for every score generated, allowing for auditing and investigation. You’d prove the system’s accuracy, robustness, and cybersecurity (Article 15).
Finally, you issue an EU Declaration of Conformity and affix the CE mark, attesting to your compliance. This entire process must be auditable by market surveillance authorities.
Sounds like a lot of work? GOOD. This is how it should be.
Path 2: Third Party Assessment
If your review scoring system involved certain biometric identification or fell under other specific categories requiring external validation (like Annex I product safety legislation), you’d need to engage a Notified Body.

This external body would audit your Quality Management System and review your technical documentation. They act as an independent verifier, adding an extra layer of scrutiny and trust. This is typically reserved for the most critical systems.
OK, what does this really mean for vendors or deployers (users of AI Systems)?
The key insight here is that for vendors, the use case defines the compliance burden.
The exact same scraping technology, the same underlying NLP models, can shift from minimal risk to high risk based entirely on how your client intends to use the “scores” you generate.
This means you need to:
- Know your intended purpose and be crystal clear about what your AI system is designed to do. (this changes? Your role changes.)
- Understand your customer’s use case and if your AI system can be used in a high risk application (even if you don’t explicitly market it for that), you bear a significant responsibility to either restrict its use or ensure it meets high risk requirements.
- Build Compliance in, not on! Retrofitting compliance is expensive and painful. Integrate risk management, data governance, and logging into your development lifecycle from day one.
Conformity assessment is a rigorous process, but it’s fundamentally how you demonstrate that your AI is trustworthy and safe.
The GDPR Connection: Complementary, Not Substitutable!
Ok, yes, the EU AI Act brings to mind GDPR, of course. And there are deep connections and similar ambitions, but their scopes remain distinct. And as I am writing this I have anxiety and second thoughts about touching on the topic, but here it goes.

Both the EU AI Act and GDPR are landmark EU regulations protecting fundamental rights. Both can have extraterritorial reach. Both carry significant financial penalties. So far so good.
Now, their focus is different. GDPR is the guardian of personal data protection. Its directives govern how you collect, process, and manage any information that identifies a living individual. The AI Act, by contrast, focuses on AI system safety and trustworthiness. It dictates how AI systems are built and used, regardless of whether they process personal data.
When an AI system processes personal data, both laws apply concurrently.
The AI Act provides the framework for the AI’s characteristics and governance, while GDPR governs the personal data within that system. A violation under the AI Act, especially if it involves personal data, will almost certainly trigger a corresponding GDPR breach. For instance, any AI Act prohibited practice involving personal data (like social scoring) would inherently violate GDPR’s principles of fairness, data minimization, and lawful basis.

IMPORTANT to know!! GDPR does not list prohibited AI systems, but it prohibits data processing activities that violate its core principles. For example, processing personal data without a lawful basis (Article 6) is forbidden.
For example, a marketing campaign uses AI to target individuals based on their inferred health conditions without explicit consent. This is a GDPR violation due to lack of a lawful basis for sensitive data (Article 9) and likely a violation of fairness (Article 5(1)(a)).
The AI Act might also classify such a system as high risk if it impacts access to services. And processing special categories of personal data (like health or biometric data for identification) is generally prohibited unless strict conditions are met (Article 9). GDPR also makes it difficult to conduct solely automated decisions with significant effects without robust safeguards (Article 22).
Okay, I know that all of this sounds complicated, and it really is, with layers of laws and articles. But what it really means for us, operating in the data and AI space, is this:
You can’t build a fancy AI system that impacts people without also being meticulous about the personal data it touches.
The AI Act wants to make sure your AI is safe and reliable, period. GDPR wants to make sure you’re respecting individual privacy, specifically their data, at every step.
If you mess up the data part, your entire AI system, no matter how compliant with the AI Act it is otherwise, can still land you in hot water. Think of it as a two key system for trust: one key for the AI’s integrity, and the other for the individual’s data rights. You need both to unlock the door to responsible innovation.
But wait Juliana, I am not an EU company, or don’t live in the EU, why should I care?
You should care. If your AI systems or data touch the EU, its markets, or its citizens, these laws likely apply to you. It’s the Brussels effect. The EU, as a massive market, often sets global standards.
The EU AI Act isn’t just for EU companies. Its rules apply if:
- You’re a “Provider” (vendor) placing AI systems on the EU market. If you develop and sell or make your AI tool available to users in the EU, regardless of where your company is based, you must comply.
- You’re a “Deployer” (user) of an AI system located in the EU. If your US company has an EU subsidiary or branch that uses AI, that EU entity must comply.
- The output of your AI system (even if run outside the EU) is used in the EU. If your US based AI generates results that directly impact individuals or decisions in the EU, you could be in scope.
To access the large EU market, your AI Systems need to meet these standards. Non-compliance can lead to massive fines.Also, if your AI system uses any personal data from EU individuals, both GDPR and the EU AI Act often apply. Yes, even bigger fines and loss of trust from the market.
In EU compliance is increasingly a non-negotiable entry ticket. Also, the EU AI Act is likely to influence future AI regulations worldwide. Getting ahead now prepares you for tomorrow.
The “Wrapper Economy” and Definitive Roles: Who’s on the Hook?
Back to our scheduled program and the topics I am known for…the widespread practice of building “AI-powered” solutions by simply integrating LLM APIs brings the distinction between roles under both acts into sharp focus.

Let’s revisit the GDPR roles:
- Data Controller: This is the entity that determines the purposes (why are we processing this data?) and the means (how are we processing it, fundamentally?) of personal data processing. The Controller holds ultimate accountability under GDPR.
- Scenario: Your marketing team runs a lead generation campaign, collecting names, emails, and company roles. Your company is the Controller of that data because you determined its purpose (lead gen) and the general method of collection.
- Data Processor: This entity processes personal data on behalf of and according to the instructions of the Controller. Processors have specific obligations, particularly around security and assisting the Controller.
- Scenario: You use a third-party CRM system to store those marketing leads. The CRM provider is your Data Processor; they store and manage the data based on your instructions.
EU AI Act Roles:
- Provider of an AI System: If you develop an AI system or commission its development and then place it on the market or put it into service under your own name or brand, you are the Provider. This role carries the most extensive obligations under the AI Act. (this is the vendor)
- Deployer of an AI System: If your organization uses an AI system in its operations (i.e., your HR team uses an AI tool for screening candidates, or your content team uses a generative AI for marketing copy). (these are companies buying, investing in tools that they add in their systems)
Example: Let’s say your company, a SaaS provider, builds an internal “Smart Recruiter” tool. This tool integrates an LLM API to summarize resumes and identify keywords for your HR team.
- Your Company (The Builder): You are the Provider of an AI System for that “Smart Recruiter” tool. Even if you’re just wrapping an external API, you’ve developed and placed your integrated system into service. As it’s used for employment (a high risk area, see Annex III), you are subject to all the stringent AI Act requirements for high risk AI. And, because it processes applicant resumes (personal data), you are also the Data Controller for that data under GDPR.
- The LLM API Vendor (like OpenAI, Google): They are the Provider of a General-Purpose AI Model (GPAI) under the AI Act, with their own specific obligations (like transparency on training data, as per Articles 53-56). Under GDPR, they would likely be a Data Processor acting on your instructions, assuming you have a robust Data Processing Agreement (DPA) in place that restricts how they use your input data for example, no model training with PII.
So the essence here is that simply connecting to an API does not outsource responsibility. Not at all.
If you’re building a product or even an internal tool that makes AI accessible and functional for a specific purpose, you are likely assuming the “Provider” role under the AI Act. This shifts significant compliance responsibility to you.
Let’s unpack this even more. Depending on how the “intended purpose” of your AI system changes over time, and how your systems develop you can easily move on from Deployer to Provider. And not only intended purpose, also things like whitelabeling, rebranding or significant changes will do the job. So, even if you just start “tweaking” or “customizing” an AI tool for your specific needs, be aware that you might be inadvertently taking on the much heavier legal burden of a Provider. It requires careful assessment of your evolving AI use cases.

Also for more on wrappers companies, I wrote about it at length here.
The Elephant in the Room: Company Data in Public LLMs
Here’s a common scenario that keeps legal and data teams up at night: an employee, seeking a quick summary or brainstorming idea, dumps company data, perhaps a client list, internal financial projections, or unreleased marketing campaign details into a publicly accessible LLM interface.
This is fundamentally a GDPR problem, not primarily an AI Act one for the AI system provider.
The EU AI Act’s primary focus is on regulating the AI system itself and its market placement.The Act does not directly regulate the casual, unauthorized misuse of publicly available LLMs by individual employees. This is a big confusion I had myself.
So, the liability for this kind of data exposure falls squarely on the company (as the Data Controller). Such an action typically violates multiple GDPR principles, including lawful basis, data minimization, purpose limitation, etc…
So, if a marketing analyst copies an entire customer segmentation report (containing PII) into GPT asking for “key insights” this directly breaches GDPR due to lack of lawful basis, purpose limitation, and adequate security.
The AI Act doesn’t directly regulate this employee action, but the company now faces GDPR liability.
For data and marketing professionals, this means internal governance and education are paramount. You need robust internal policies, clear guidelines on using AI tools, and ongoing training to prevent employees from becoming inadvertent data leak points.
So, in the end, the AI Act’s regulatory teeth bite hard on the builders (Providers) of AI systems. It mandates comprehensive documentation, rigorous conformity assessments, proactive risk management systems, and continuous post market monitoring. This is a framework built for serious compliance, not casual deployment.
Finally, my Take: The AI Act is a “Compliance Moat”

Here’s something I think many in the vendor space are missing to understand, the EU AI Act is not a burden, but an opportunity to build a “compliance moat.”
We’ve all heard of the “data moat”, the idea that proprietary data gives you an insurmountable competitive advantage. Well, the AI Act makes me think of a “compliance moat.” Early and robust compliance with this regulation will become a significant differentiator, especially for B2B AI solutions.
What am I seeing / predicting?
- Vendors selling “compliant AI” will win contracts. Your clients, the deployers, will be looking for AI systems that minimize their compliance burden. If you can deliver a high risk AI system with clear documentation, a robust risk management system, and demonstrable human oversight mechanisms built in, you’re offering a product that derisks their adoption.
For example, ifyour company offers an AI powered sales forecasting tool (potentially high risk if it determines sales quotas that significantly affect employee performance). You invest early in AI Act compliance, developing clear technical documentation, implementing robust data governance for your training data, and providing easy to use human oversight features for your clients. You can now market your tool as “EU AI Act Ready,” giving you a tangible edge over competitors who might be faking the funk. - Disciplined product development. The Act’s requirements, particularly for high risk AI, mandate clear methodologies, rigorous testing, and continuous monitoring. This means building better, more reliable, and more auditable AI systems. This translates directly to higher quality products, fewer bugs, and ultimately, greater customer satisfaction.
- Building trust beyond the spec sheet. You don’t want to be seen as a “black box” AI system, and if you demonstrate commitment to the AI Act’s principles: transparency, fairness, accountability builds profound customer trust. This trust converts directly into market share and stronger lon -term relationships, especially in regulated industries like finance, healthcare, and HR.
Vendors who see compliance as a strategic investment, not just a cost center, will be the ones that truly thrive in the European market and, frankly, set the standard globally.
Panic or Performance: Your Choice

Panic offers no strategic advantage. However, complacency is even worse. The EU AI Act is not a distant threat, it’s an active, evolving regulatory space..
And as I said, I see this as an opportunity. Organizations that proactively engage with the EU AI Act will distinguish themselves. They’ll build trust, mitigate unforeseen risks, and position themselves as responsible innovators in a rapidly maturing AI market. Embracing these requirements is simply good business practice.
And for us, the operators in the AI space, we need to fully understand this Act and its goals and make sure that no matter where we are and what we do, to put our clients, and company’s wellbeing first and not get caught up in the hype.
We must do our best to protect the people that trust us with their workflows and data 😉 – I learnt that saying from Aurelie in our last call 🙂
So, what can you do right now?
- Start by identifying every AI system your organization uses or develops. Know your inventory.
- Make sure your workforce is AI-literate regarding the tasks that fall under their responsibility (addition from Fabrizio Bianchi, this is a general requirement – already active – under the AI ACT)
- For each AI system, meticulously assess its risk level under the EU AI Act’s categories. This step dictates your compliance pathway.
- Ensure all personal data processing, from collection to deletion, aligns strictly with GDPR. Implement robust internal policies and technical safeguards (i.e data loss prevention, data masking) to prevent unauthorized data input into LLMs, if you haven’t already.
- Push for serious training for all teams on both GDPR and AI Act principles, emphasizing responsible data handling and AI tool usage.
- Establish clear internal processes for AI system development, deployment, risk management, and documentation. This requires cross-functional collaboration between your legal, tech, product, and marketing teams.
- Legal counsel and AI ethics experts are essential partners in navigating these complex regulatory waters.
The EU AI Act is a significant challenge, but it’s also a clear pathway to building more robust, ethical, and trustworthy AI.
And if you read until here, thank you for your time and hope this was helpful.
Pingback: BP 147: News Juli 2025 "Die letzte Sendung zu GA4" Podcast